HOVER (Humanoid Versatile Controller)
Summary
Humanoid Versatile Controller (HOVER) is a humanoid whole-body controller that unifies multiple command spaces into one a single neural network that can be masked at inference time to act like any of the prior task-specific specialist controllers. It uses a policy distillation framework applied on top of a goal-conditioned RL that uses PPO for the oracle (teacher) and DAgger for the student. It shows an outperformance over the policies trained individually.
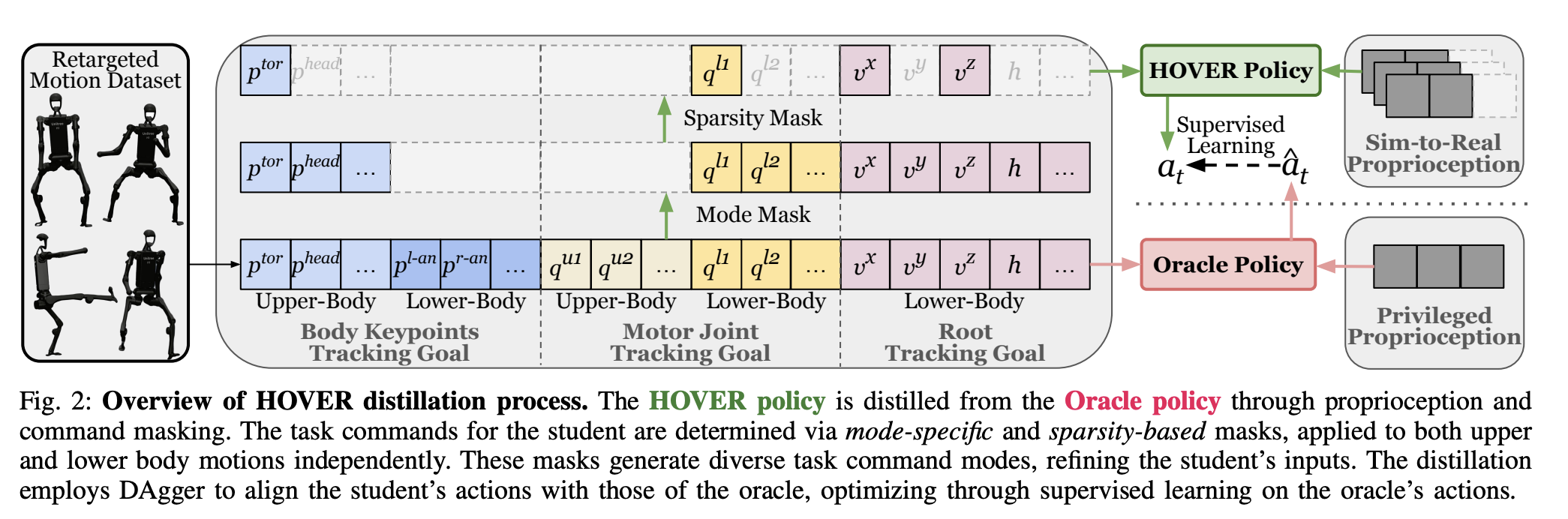
Command spaces

The above table shows command spaces for HOVER which is composed of two primary control regions and three distinct control modes for each region: 1) upper-body and lower-body, and 2) kinematic position tracking, local joint angle tracking, and root tracking.
The multi-mode control in the above table means that one policy can be operated under different command configurations. In other words, a multi-mode policy can produce good whole-body motion even when given only a partial/sparse command, because it learned to handle arbitrary command subsets with sparsity masking (which we will discuss later).
Dataset Preparation (Motion Retargeting)
Recent works have shown the advantage of learning robus whole-body control for humanoid robots from large motion datasets. The paper uses AMASS as a training dataset for HOVER. However, AMASS is represented using the SMPL body model, which is completely different from 19-DOF Unitree H1 robot. Therefore, we need to retarget the human motion into a motion that is physically feasible for humanoid robot.
Policy Distillation
HOVER uses a teacher-student policy distillation to solve the hard motion-control problem. But why not RL directly? If we train the policy with RL directly, it will struggle with the credit-assignment problem due to a randomized partial observability. Hence, we train one privileged, full-information “oracle” policy via PPO on pure motion imitation, then distill it into the masked, partial-observation “student” policy via DAgger.
The paper compares the performance of HOVER with that of another multi-mode RL policy which follows the same masking process but trains the baseline with RL objective from scratch, and shows that HOVER achieves consistently lower tracking error across 32/32 metrics and modes.
Oracle Policy Training
As mentioned earlier, the oracle policy $\pi^{\text{oracle}}(a_t \mid s_t^{\text{p-oracle}}, s_t^{\text{g-oracle}})$ is trained via PPO using the retargeted motion dataset $\hat{Q}$. Here, $s_t^{\text{p-oracle}} \triangleq [p_t, \theta_t, \dot{p_t}, \omega_t, a_{t-1}]$ is a proprioception state which basically contains the current state of the humanoid and the previous action. $s_t^{\text{g-oracle}} \triangleq [\hat{\theta_{t+1}} \ominus \theta_t, \hat{p_{t+1}} - p_t, \hat{v_{t+1}} - v_t, \hat{\omega_{t+1}} - \omega_t, \hat{\theta_t}, \hat{p_t}]$ is a goal state which contains the one-frame difference between the next reference and current state, belong to the current reference state.
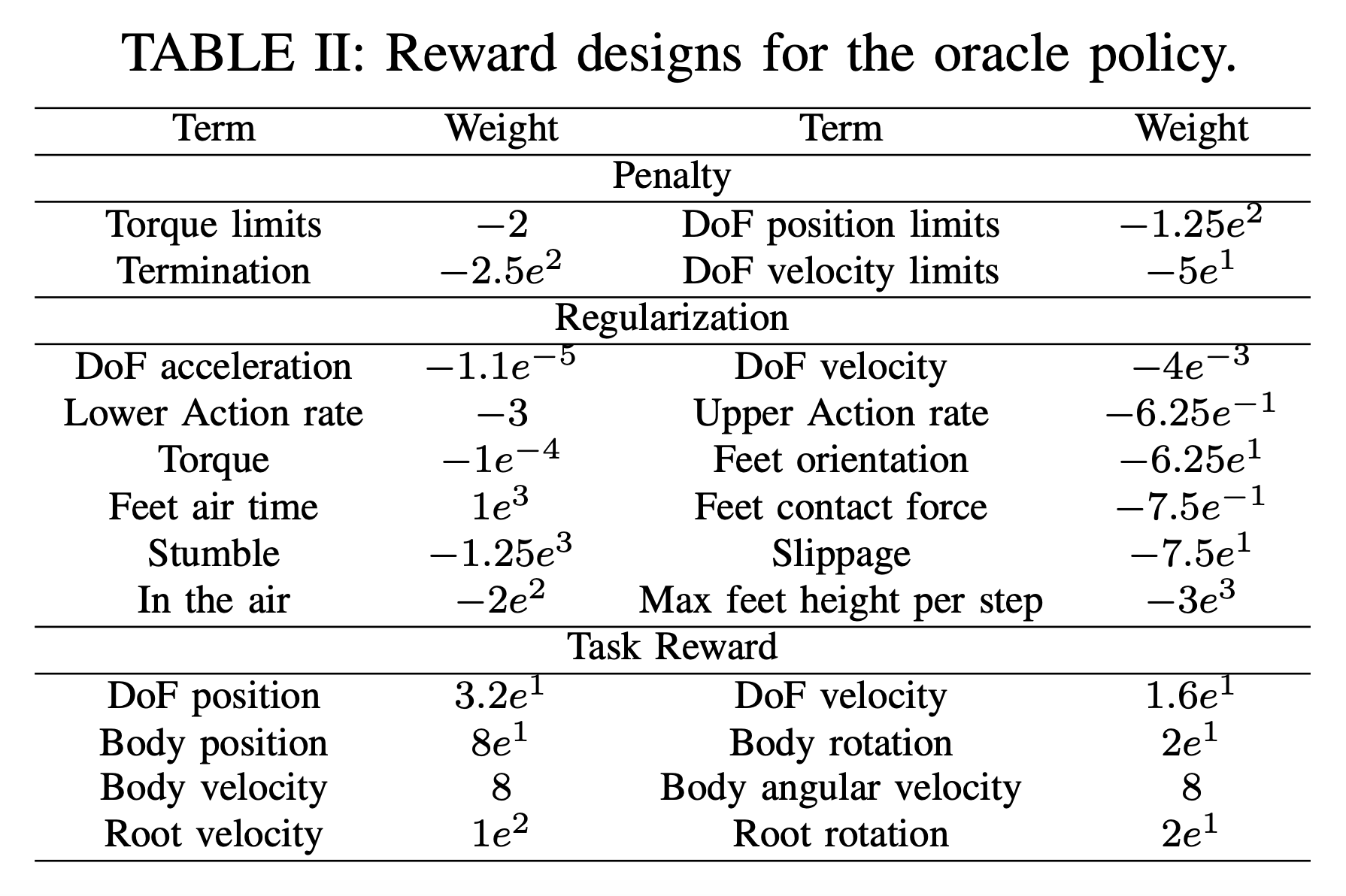
Then, how can we define the reward function $\mathcal{R}(s_t^p, s_t^g)$? HOVER formulates the reward as the sum of 1) penalty, 2) regularization, and 3) task reward. First, the penalty term guards hard boundaries and failure events (“Did you do something forbidden / dangerous / catastrophic?”). Second, the regularization term shapes how the motion is executed among the many valid ways to achieve the same task reward (“How to do something smoothly / efficiently?”). Lastly, the task reward measures the closeness between current state and reference motion (“Did you achieve the objective?”). You can see a more detailed reward designs for the oracle policy at the below table.
Student Policy Training
As mentioned earlier, the student policy $\pi^{\text{student}}(s_t^{\text{p-student}}, s_t^{\text{g-student}})$ is learned from the oracle teacher policy via DAgger. The proprioception state for the student policy is defined as follows: $s_t^{\text{p-student}} \triangleq [q, \dot{q}, \omega^{\text{base}}, g]_{t-25:t} \cup [a_{t-25:t-1}]$. In addition, the goal state is represented as $s_t^{\text{g-student}} \triangleq M_{\text{sparsity}} \odot \Big[ M_{\text{mode}} \odot s_t^{\text{g-upper}}, M_{\text{mode}} \odot s_t^{\text{g-lower}} \Big]$ where $M_{\text{mode}}$ is a mode mask selecting which command type is active per body region and $M_{\text{sparsity}}$ is a sparsity mode selecting which specific dimensions within that mode are active. Both masks are i.i.d Bernoulli distribution $\mathcal{B}(0.5)$ per bit, resampled per episode and held fixed within it.
HOVER is a follower, not a doer
Note that HOVER is not a system that takes the task and executes it. A command source (a learned higher-level policy, a human teleoperator, or a reference clip) produces the goal-state stream, capturing the task-level intent. HOVER then consumes that goal state together with the robot’s current proprioception to produce, at each frame, an action that is safe (penalties), smooth/efficient (regularization), and on-target (task tracking) — i.e., a balanced physical realization of the commanded motion.
Limitations
No automated mode-switching
HOVER unifies the execution of modes but not the decision of which mode to use when. The mask must be supplied externally (by a human operator, a teleoperation device, or a higher-level system).
Bounded by oracle quality and data distribution
The student can be at most as good as the privileged oracle, and the oracle can only imitate motions in the retargeted AMASS dataset $\hat{Q}$.
Single embodiment
Everything is validated on one robot, the 19-DOF Unitree H1. The retargeting, the reward limits, and the trained policy are all tied to that body. No cross-embodiment transfer is demonstrated.
Heavily hand-engineered, brittle reward
The reward is ~23 weighted terms with weights spanning eight orders of magnitude and per-term sigmas, all hand-tuned and inherited from prior work (OmniH2O/legged_gym). This is fragile and non-portable: there’s no principled way to set these, and tuning them for a new robot or new motion regime is real labor.