DUSDi (Disentangled Unsupervised Skill Discovery)
Summary
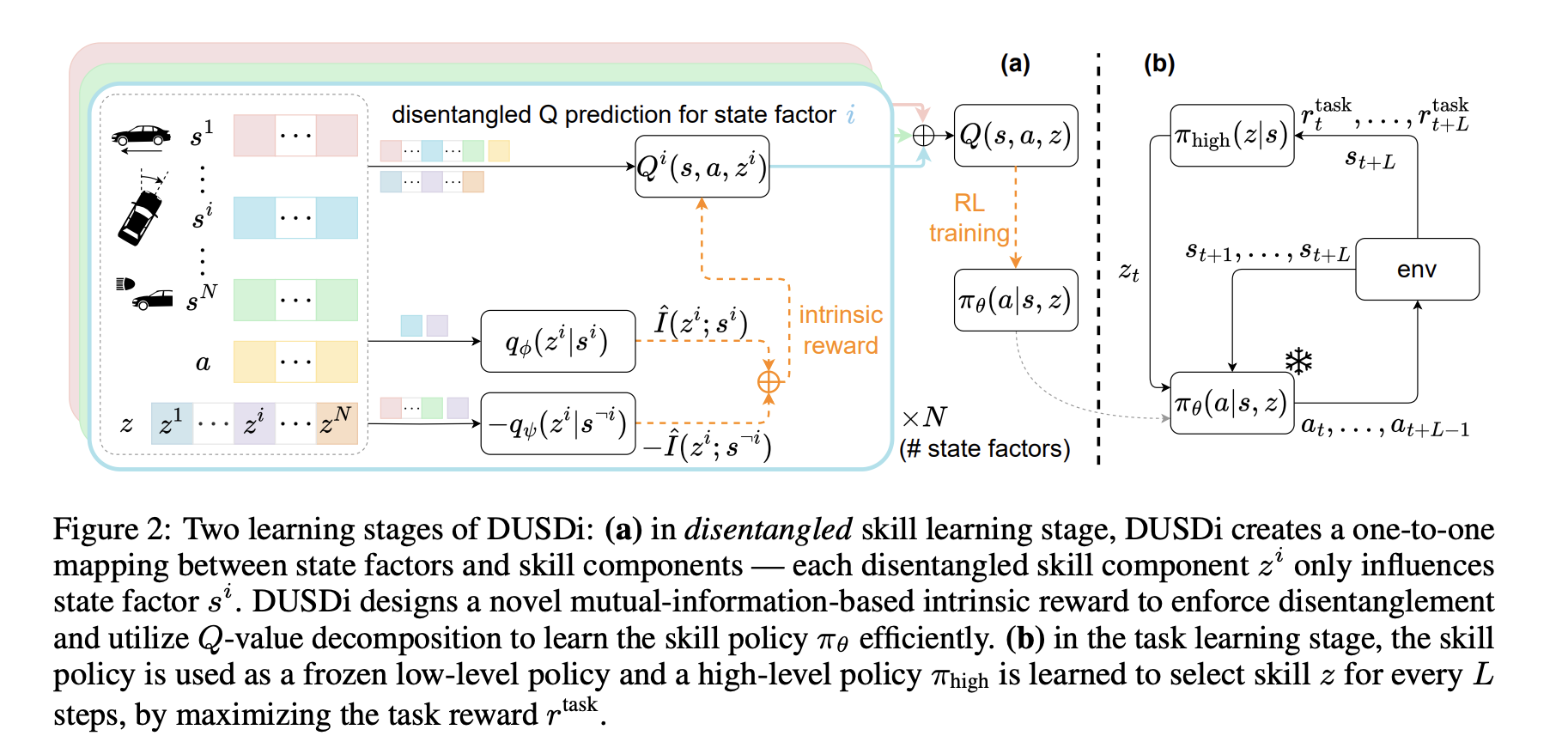
Disentangled Unsupervised Skill Discovery (DUSDi) is a method for learning disentangled skills in factored state spaces.
Disentanglement
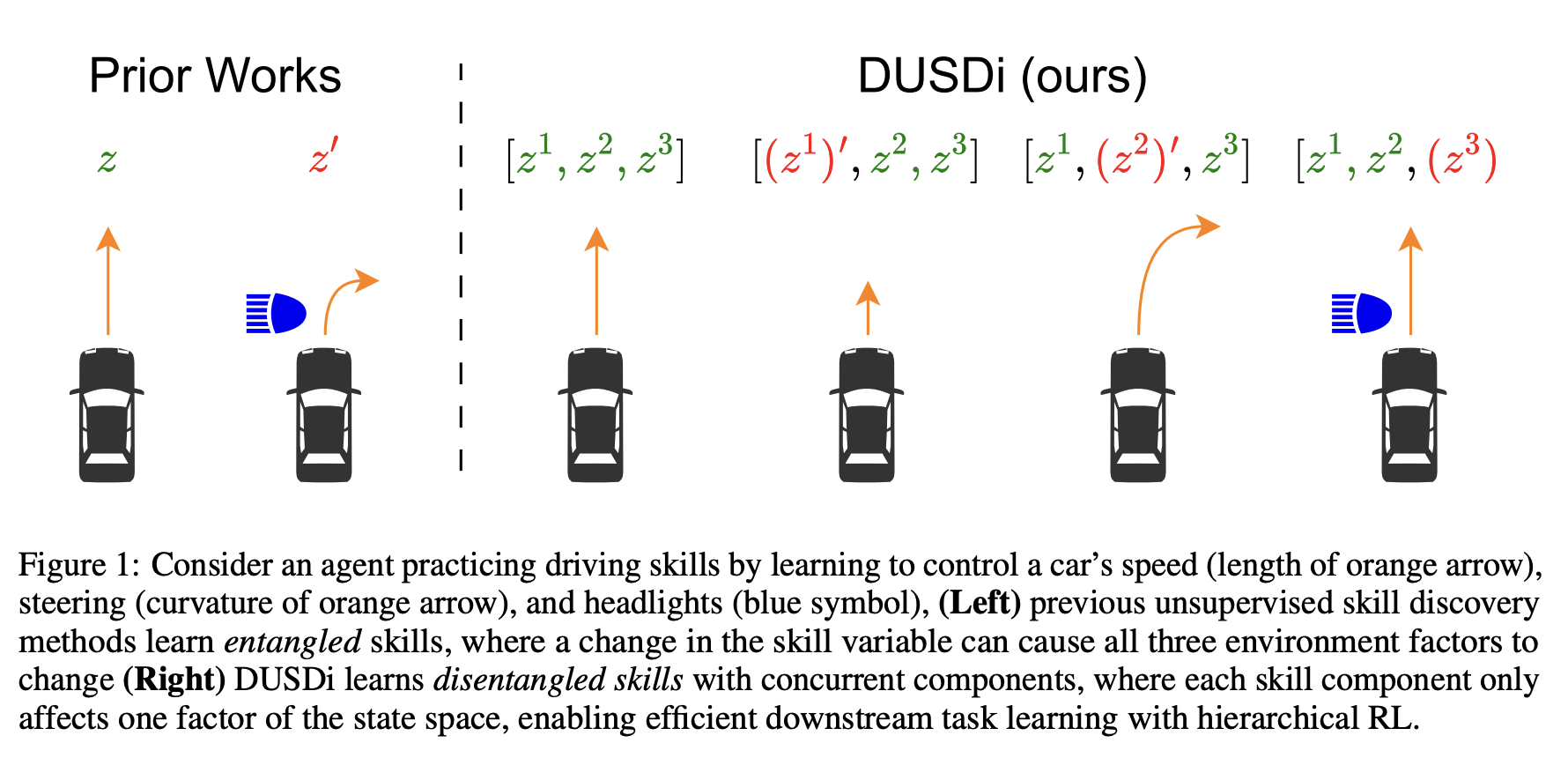 What does it mean by the skills are disentangled?
What does it mean by the skills are disentangled?
The paper gives an example of driving a car to compare between prior work and DUSDi. If a single skill variable simultaneously changes the speed, steering, and headlights, it will be extremely challenging to learn how to turn the headlights on/off while keeping the car at the right speed and direction; it requires a complicated combination of skill variables. However, if a skill variable $z_1$ controls only speed, $z_2$ only steering, and $z_3$ only headlights, the agent could simply do the above command by fixing $z_1$ and $z_2$ and modulating $z_3$.
Prior works suffer from entangled skills: any change in the skill variable causes the agent to induce changes in multiple dimensions of the state space simultaneously. DUSDi resolves this issue by decomposing skills into disentangled components and encouraging each skill component to affect only one state factor.
Factored State Space
In mathematical expression, $\mathcal{S} = \mathcal{S}^1 \times \cdots \times \mathcal{S}^N$ is a factored state space with $N$ factors such that each state $s \in S$ consists of $N$ state factors: $s = (s^1, \cdots, s^N), s^i \in \mathcal{S}^i$.
Then, is there a way to convert from unfactored state space (e.g., pixel images) into factored state space? First, we might be able to use $\beta$-VAE to encode the state space to the latent space which we can treat as a factored state space. Secondly, we can use an object-centric representation learning where each slot in latent space represents one object. The paper runs the experiment on unfactored state space using a latter method.
Disentanglement Objective
Let’s define the factored skill space as $\pi_\theta : \mathcal{S} \times \mathcal{Z} \rightarrow \mathcal{A}$ where each disentangled componenet $\mathcal{Z}^i$ only affects the value of a state factor $\mathcal{S}^i$. We want to maximize the mutual information $I(\mathcal{S}^i; \mathcal{Z}^i)$ but minimizing $I(\mathcal{S}^{\neg i}, \mathcal{Z}^i)$.
\[\mathcal{J}(\theta) = \sum_{i=1}^N I(\mathcal{S}^i; \mathcal{Z}^i) - \lambda I(\mathcal{S}^{\neg i}; \mathcal{Z}^i)\]Here, $\lambda$ is a hyperparameter adjusting the importance of the entanglement penalty relative to the skill-factor association.
However, calculating the mutual information is intractable. Therefore, we will introduce the variational distribution $q_\phi^i$ and $q_{\psi}^i$.
\[I(\mathcal{S}^i; \mathcal{Z}^i = H(\mathcal{Z}^i) - H(\mathcal{Z}^i \mid \mathcal{S}^i) \geq C + \mathbb{E}_{z, s} \log q_{\phi}^i(z^i \mid s^i)\] \[I(\mathcal{S}^{\neg i}; \mathcal{Z}^i) \geq C + \mathbb{E}_{z, s} \log q_{\phi}^i (z^i|s^{\neg i})\]Combining the above equation,
\[r_z(s, a) \triangleq \sum_{i=1}^N q_{\phi}^i (z^i \mid s^i) - \lambda q_{\psi}^i(z^i \mid s^{\neg i})\]Here, we can think that the above surrogative is not a true lower bound on $J(\theta)$ since we are subtracting the lower bound from the lower bound. However, the paper treats it as an accepted approximation due to the complexity in upper bounding MIs. (Also, I think $\lambda = 0.1 < 1$ prevents the penalty term to dominate)
Q Decomposition
Since the intrinsic reward term is linear in $i$ and the expectation is linear, we can decompose the Q-function for the whole reward as the sum of the $N$ disentangled Q-functions.
\[Q_\phi(s, a, z) = \sum_{i=1}^N Q^i(s, a, z)\]Then, what are the advantages of decomposing $Q_\phi$? Compared to learning $Q_\phi$ directly from all $2N$ reward terms, learning disentangled Q functions significantly reduces reward variance, allowing $Q_\phi$ to converge faster and more stably.
Pseudocode

Task learning stage