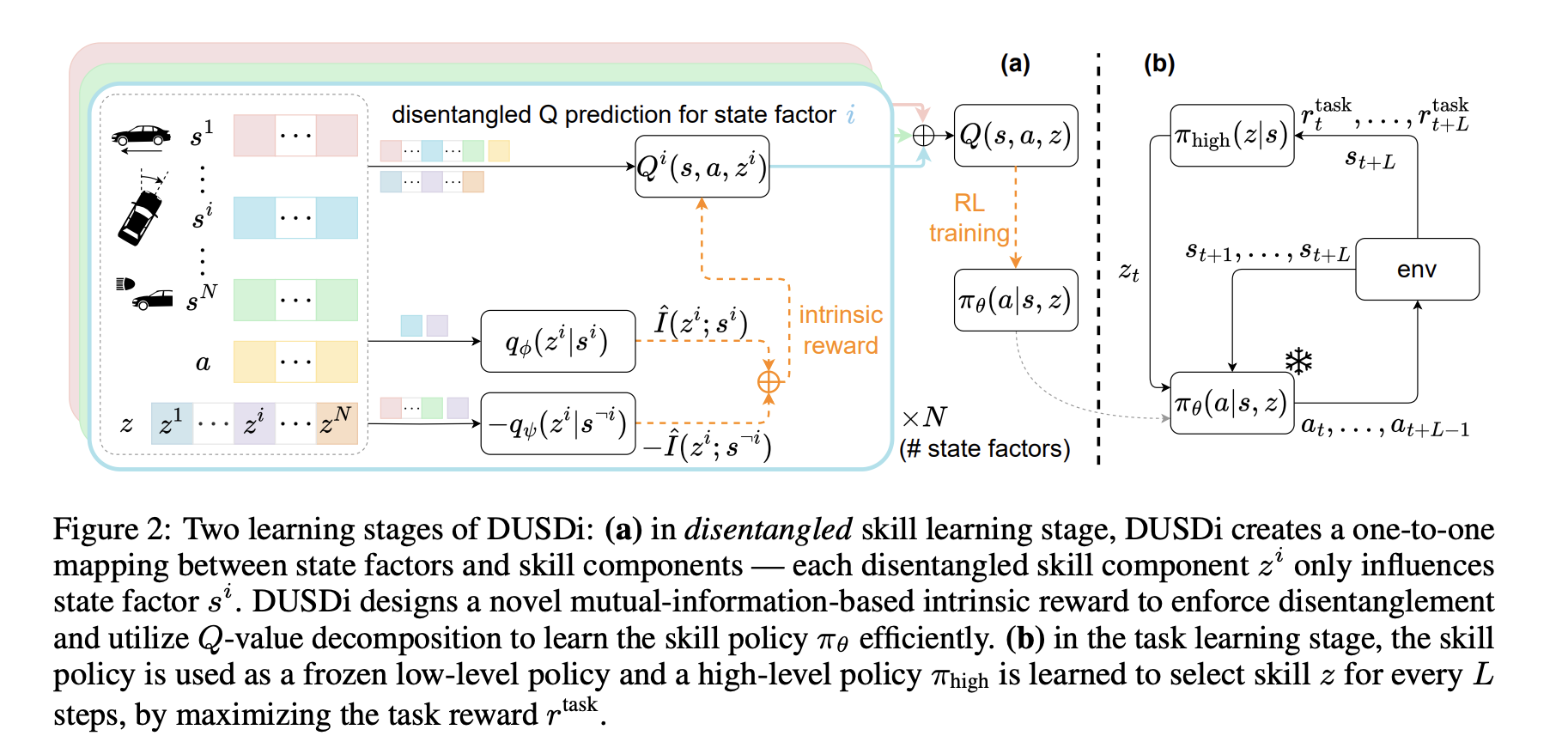
DUSDi (Disentangled Unsupervised Skill Discovery)
요약
DUSDi(Disentangled Unsupervised Skill Discovery)는 요인화된 상태 공간(factored state space)에서 분리된(disentangled) 스킬을 학습하는 방법입니다.
Disentanglement
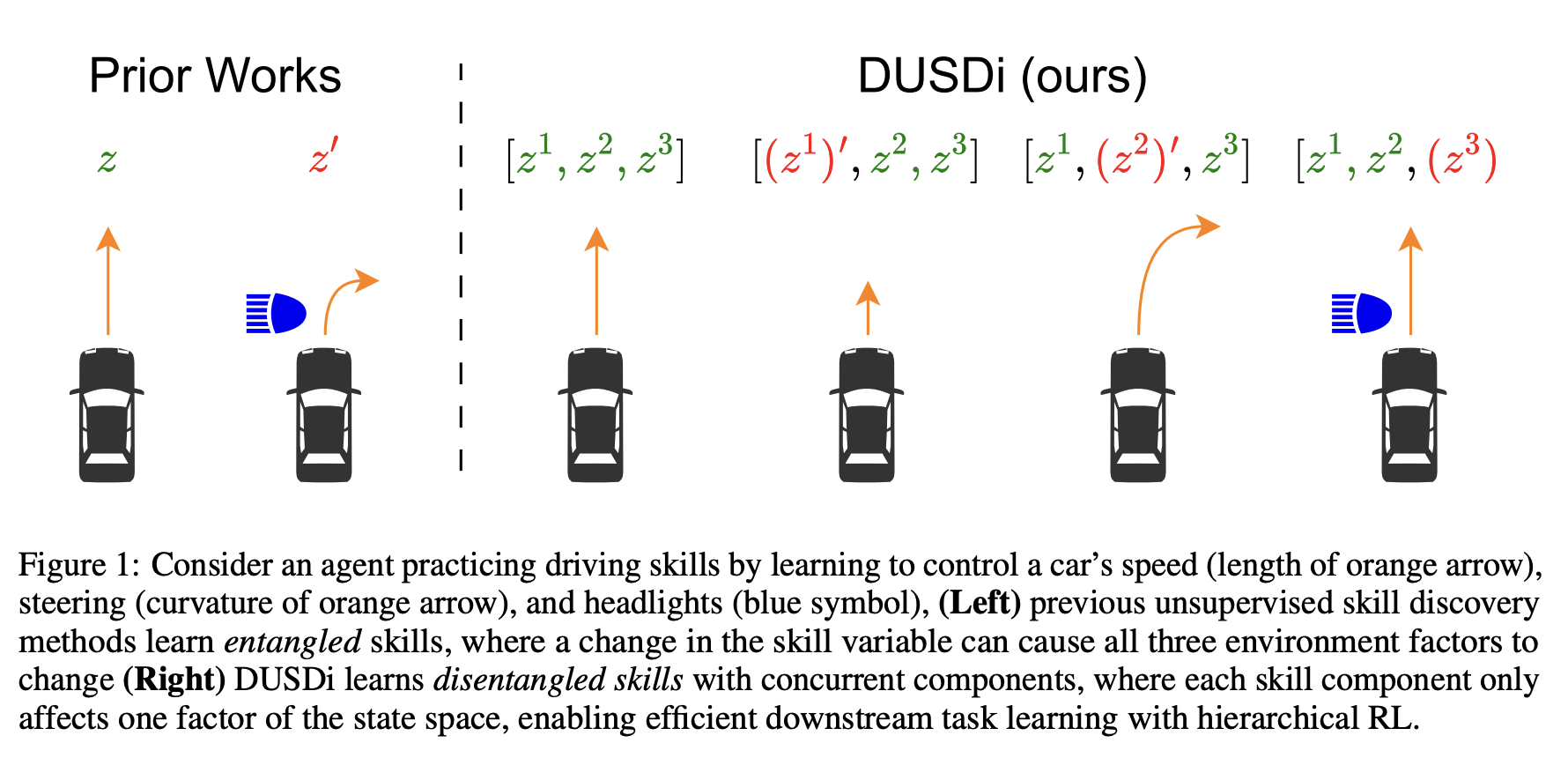 스킬이 분리되어 있다는 것은 무슨 의미일까요?
스킬이 분리되어 있다는 것은 무슨 의미일까요?
논문에서는 자동차 운전을 예시로 들어 기존 연구와 DUSDi를 비교합니다. 하나의 스킬 변수가 속도, 조향, 헤드라이트를 동시에 바꾼다면, 차의 속도와 방향을 유지하면서 헤드라이트만 켜고 끄는 것은 여러 스킬 변수를 복잡하게 조합해야 하므로 매우 어려운 일이 됩니다. 하지만 스킬 변수 $z_1$이 속도만, $z_2$가 조향만, $z_3$가 헤드라이트만 제어한다면, 에이전트는 $z_1$과 $z_2$를 고정한 채 $z_3$만 조절하여 위 명령을 간단히 수행할 수 있습니다.
기존 연구들은 얽혀 있는(entangled) 스킬 문제를 겪습니다. 즉, 스킬 변수의 어떤 변화든 에이전트가 상태 공간의 여러 차원을 동시에 변화시키게 만듭니다. DUSDi는 스킬을 분리된 구성요소로 분해하고, 각 스킬 구성요소가 오직 하나의 상태 요인에만 영향을 주도록 함으로써 이 문제를 해결합니다.
Factored State Space
수식으로 표현하면, $\mathcal{S} = \mathcal{S}^1 \times \cdots \times \mathcal{S}^N$은 $N$개의 요인을 가진 요인화된 상태 공간이며, 각 상태 $s \in S$는 $N$개의 상태 요인으로 구성됩니다: $s = (s^1, \cdots, s^N), s^i \in \mathcal{S}^i$.
그렇다면 비요인화된 상태 공간(예: 픽셀 이미지)을 요인화된 상태 공간으로 변환할 방법이 있습니까? 첫째, $\beta$-VAE를 사용해 상태 공간을 잠재 공간으로 인코딩하고, 이를 요인화된 상태 공간으로 취급할 수 있습니다. 둘째, 잠재 공간의 각 슬롯이 하나의 객체를 나타내는 객체 중심(object-centric) 표현 학습을 사용할 수 있습니다. 논문은 두 번째 방법을 사용해 비요인화된 상태 공간에서 실험을 진행합니다.
Disentanglement Objective
요인화된 스킬 공간을 $\pi_\theta : \mathcal{S} \times \mathcal{Z} \rightarrow \mathcal{A}$로 정의합니다. 이때 각 분리된 구성요소 $\mathcal{Z}^i$는 오직 상태 요인 $\mathcal{S}^i$의 값에만 영향을 줍니다. 우리는 상호정보량 $I(\mathcal{S}^i; \mathcal{Z}^i)$는 최대화하면서 $I(\mathcal{S}^{\neg i}, \mathcal{Z}^i)$는 최소화하고자 합니다.
\[\mathcal{J}(\theta) = \sum_{i=1}^N I(\mathcal{S}^i; \mathcal{Z}^i) - \lambda I(\mathcal{S}^{\neg i}; \mathcal{Z}^i)\]여기서 $\lambda$는 엔탱글먼트 페널티가 스킬-요인 연관성에 비해 얼마나 중요한지를 조절하는 하이퍼파라미터입니다.
하지만 상호정보량을 직접 계산하는 것은 불가능(intractable)합니다. 따라서 변분 분포(variational distribution) $q_\phi^i$와 $q_{\psi}^i$를 도입합니다.
\[I(\mathcal{S}^i; \mathcal{Z}^i = H(\mathcal{Z}^i) - H(\mathcal{Z}^i \mid \mathcal{S}^i) \geq C + \mathbb{E}_{z, s} \log q_{\phi}^i(z^i \mid s^i)\] \[I(\mathcal{S}^{\neg i}; \mathcal{Z}^i) \geq C + \mathbb{E}_{z, s} \log q_{\phi}^i (z^i|s^{\neg i})\]위 두 식을 결합하면,
\[r_z(s, a) \triangleq \sum_{i=1}^N q_{\phi}^i (z^i \mid s^i) - \lambda q_{\psi}^i(z^i \mid s^{\neg i})\]여기서 위 식은 하한(lower bound)에서 또 다른 하한을 빼는 형태이므로 $J(\theta)$에 대한 엄밀한 하한은 아니라고 볼 수 있습니다. 그러나 상호정보량의 상한을 구하는 것이 복잡하기 때문에, 논문은 이를 받아들일 수 있는 근사로 취급합니다. (또한 $\lambda = 0.1 < 1$이므로 페널티 항이 전체를 지배하지 않도록 막아준다고 생각합니다)
Q Decomposition
내재적 보상(intrinsic reward) 항이 $i$에 대해 선형이고 기댓값 연산도 선형이므로, 전체 보상에 대한 Q 함수를 $N$개의 분리된 Q 함수의 합으로 분해할 수 있습니다.
\[Q_\phi(s, a, z) = \sum_{i=1}^N Q^i(s, a, z)\]그렇다면 $Q_\phi$를 분해하는 것의 장점은 무엇입니까? 모든 $2N$개의 보상 항으로부터 $Q_\phi$를 직접 학습하는 것과 비교했을 때, 분리된 Q 함수들을 학습하면 보상 분산이 크게 감소하여 $Q_\phi$가 더 빠르고 안정적으로 수렴할 수 있습니다.
Pseudocode

Task learning stage