HOVER (Humanoid Versatile Controller)
Summary
Humanoid Versatile Controller (HOVER)는 multiple command spaces를 하나의 single neural network로 통합하는 humanoid whole-body controller로, inference 시점에 masking을 통해 기존의 task-specific specialist controller처럼 동작할 수 있습니다. goal-conditioned RL 위에 policy distillation framework를 적용하며, oracle (teacher)에는 PPO, student에는 DAgger를 사용합니다. 개별적으로 학습된 policy들에 비해 우수한 성능을 보입니다.
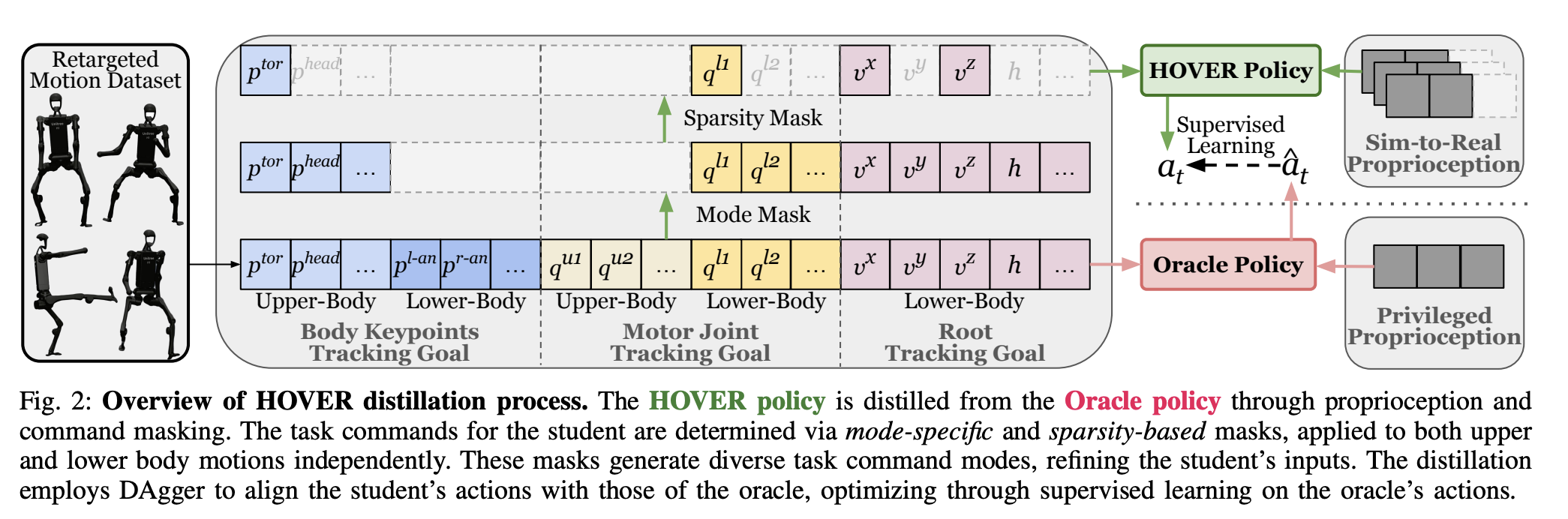
Command spaces

위 표는 HOVER의 command space를 나타내며, 두 가지 주요 control region과 각 region에 대한 세 가지 control mode로 구성됩니다: 1) upper-body와 lower-body, 2) kinematic position tracking, local joint angle tracking, root tracking.
위 표의 multi-mode control은 하나의 policy가 서로 다른 command configuration 하에서 동작할 수 있음을 의미합니다. 즉, multi-mode policy는 임의의 command subset을 처리하도록 sparsity masking으로 학습되었기 때문에, 부분적이거나 희소한 command만 주어지더라도 좋은 whole-body motion을 생성할 수 있습니다 (이에 대해서는 이후에 다루겠습니다).
Dataset Preparation (Motion Retargeting)
최근 연구들은 대규모 motion dataset으로부터 humanoid robot의 강건한 whole-body control을 학습하는 것의 이점을 보여주었습니다. 본 논문은 HOVER의 학습 dataset으로 AMASS를 사용합니다. 그러나 AMASS는 SMPL body model로 표현되어 있으며, 이는 19-DOF Unitree H1 robot과 완전히 다릅니다. 따라서 인간의 motion을 humanoid robot이 물리적으로 실현 가능한 motion으로 retargeting해야 합니다.
Policy Distillation
HOVER는 어려운 motion control 문제를 해결하기 위해 teacher-student policy distillation을 사용합니다. 그렇다면 왜 RL을 직접 사용하지 않는 것일까요? Policy를 RL로 직접 학습시키면 randomized partial observability로 인한 credit-assignment problem에 어려움을 겪게 됩니다. 따라서 순수 motion imitation에 대해 PPO로 privileged, full-information “oracle” policy를 먼저 학습시킨 뒤, DAgger를 통해 masked, partial-observation “student” policy로 distill합니다.
본 논문은 HOVER의 성능을 동일한 masking 과정을 따르되 RL objective로 처음부터 baseline을 학습시키는 또 다른 multi-mode RL policy와 비교하며, HOVER가 32/32개의 metric과 mode 전반에 걸쳐 일관되게 낮은 tracking error를 달성함을 보여줍니다.
Oracle Policy Training
앞서 언급한 바와 같이, oracle policy $\pi^{\text{oracle}}(a_t \mid s_t^{\text{p-oracle}}, s_t^{\text{g-oracle}})$은 retargeting된 motion dataset $\hat{Q}$를 사용하여 PPO로 학습됩니다. 여기서 $s_t^{\text{p-oracle}} \triangleq [p_t, \theta_t, \dot{p_t}, \omega_t, a_{t-1}]$은 proprioception state로, 기본적으로 humanoid의 현재 state와 이전 action을 포함합니다. $s_t^{\text{g-oracle}} \triangleq [\hat{\theta_{t+1}} \ominus \theta_t, \hat{p_{t+1}} - p_t, \hat{v_{t+1}} - v_t, \hat{\omega_{t+1}} - \omega_t, \hat{\theta_t}, \hat{p_t}]$는 goal state로, 다음 reference state와 현재 state 간의 한 frame 차이 및 현재 reference state를 포함합니다.
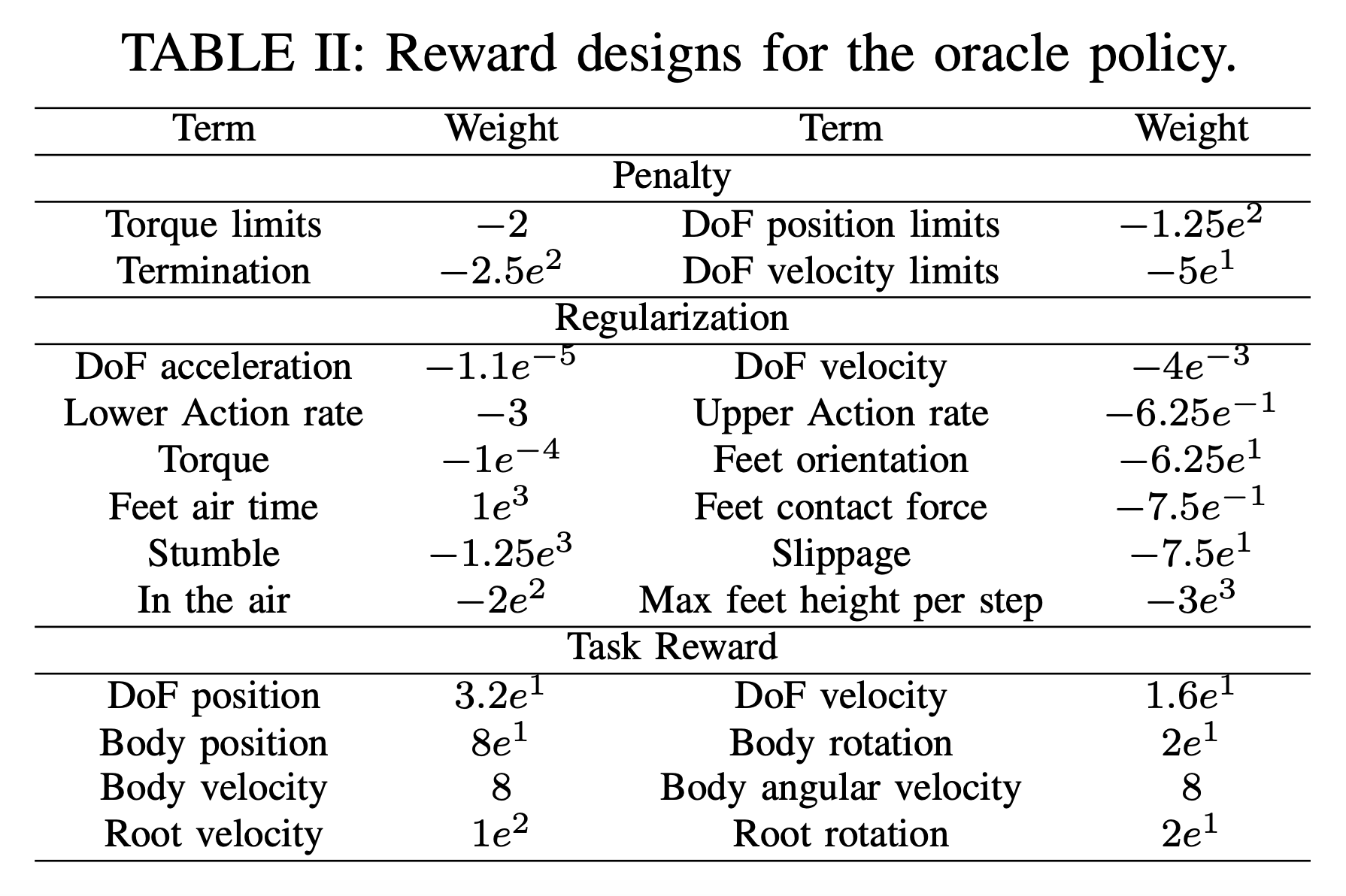
그렇다면 reward function $\mathcal{R}(s_t^p, s_t^g)$는 어떻게 정의할까요? HOVER는 reward를 1) penalty, 2) regularization, 3) task reward의 합으로 정식화합니다. 먼저 penalty 항은 엄격한 경계와 실패 사건을 방지합니다(“금지되거나 위험하거나 치명적인 행동을 했습니까?”). 다음으로 regularization 항은 동일한 task reward를 달성하는 여러 유효한 방법 중에서 motion이 실행되는 방식을 형성합니다(“어떻게 하면 부드럽고 효율적으로 할 수 있습니까?”). 마지막으로 task reward는 현재 state와 reference motion 간의 유사도를 측정합니다(“목표를 달성했습니까?”). Oracle policy에 대한 더 자세한 reward 설계는 아래 표에서 확인할 수 있습니다.
Student Policy Training
앞서 언급한 바와 같이, student policy $\pi^{\text{student}}(s_t^{\text{p-student}}, s_t^{\text{g-student}})$은 DAgger를 통해 oracle teacher policy로부터 학습됩니다. Student policy의 proprioception state는 다음과 같이 정의됩니다: $s_t^{\text{p-student}} \triangleq [q, \dot{q}, \omega^{\text{base}}, g]_{t-25:t} \cup [a_{t-25:t-1}]$. 또한 goal state는 $s_t^{\text{g-student}} \triangleq M_{\text{sparsity}} \odot \Big[ M_{\text{mode}} \odot s_t^{\text{g-upper}}, M_{\text{mode}} \odot s_t^{\text{g-lower}} \Big]$로 표현됩니다. 여기서 $M_{\text{mode}}$는 각 body region에서 어떤 command type이 활성화되는지를 선택하는 mode mask이며, $M_{\text{sparsity}}$는 해당 mode 내에서 어떤 특정 dimension이 활성화되는지를 선택하는 sparsity mask입니다. 두 mask 모두 bit당 i.i.d Bernoulli distribution $\mathcal{B}(0.5)$를 따르며, episode마다 재샘플링되고 episode 내에서는 고정됩니다.
HOVER is a follower, not a doer
HOVER는 task를 받아 직접 실행하는 시스템이 아님에 유의하십시오. Command source (학습된 higher-level policy, 인간 원격 조작자, 또는 reference clip)가 goal-state stream을 생성하여 task-level intent를 포착합니다. HOVER는 그 goal state와 robot의 현재 proprioception을 함께 입력받아, 매 frame마다 안전하고(penalty), 부드럽고 효율적이며(regularization), 목표에 부합하는(task tracking) action, 즉 명령된 motion의 균형 잡힌 물리적 실현을 출력합니다.
Limitations
No automated mode-switching
HOVER는 mode의 실행을 통합하지만, 언제 어떤 mode를 사용할지에 대한 결정은 통합하지 않습니다. Mask는 인간 조작자, 원격 조작 장치, 또는 상위 레벨 시스템에 의해 외부에서 제공되어야 합니다.
Bounded by oracle quality and data distribution
Student는 privileged oracle보다 뛰어날 수 없으며, oracle은 retargeting된 AMASS dataset $\hat{Q}$에 있는 motion만 모방할 수 있습니다.
Single embodiment
모든 검증은 19-DOF Unitree H1이라는 하나의 robot에서만 이루어집니다. Retargeting, reward 한계, 학습된 policy 모두 해당 robot에 종속되어 있으며, 다른 robot 구조로의 전이는 검증되지 않았습니다.
Heavily hand-engineered, brittle reward
Reward는 여덟 자릿수에 걸친 가중치와 항별 sigma를 가진 약 23개의 weighted term으로 구성되며, 모두 수작업으로 조정되고 선행 연구(OmniH2O/legged_gym)로부터 상속된 것입니다. 이는 취약하고 이식성이 없습니다: 이러한 값들을 설정하는 원칙적인 방법이 없으며, 새로운 robot이나 새로운 motion regime에 맞게 조정하는 것은 상당한 수작업이 필요합니다.